|
|
|
|
|
|
||
|
|
|
|
|
IS INTELLIGENCE DISTRIBUTED NORMALLY?By CYRIL BURTwith
informative graph prepared by abelard, |
 |
|||
|
|
||||
There are many complex characters in this paper; if you find them difficult to distinguish, you are advised to increase the viewing size. |
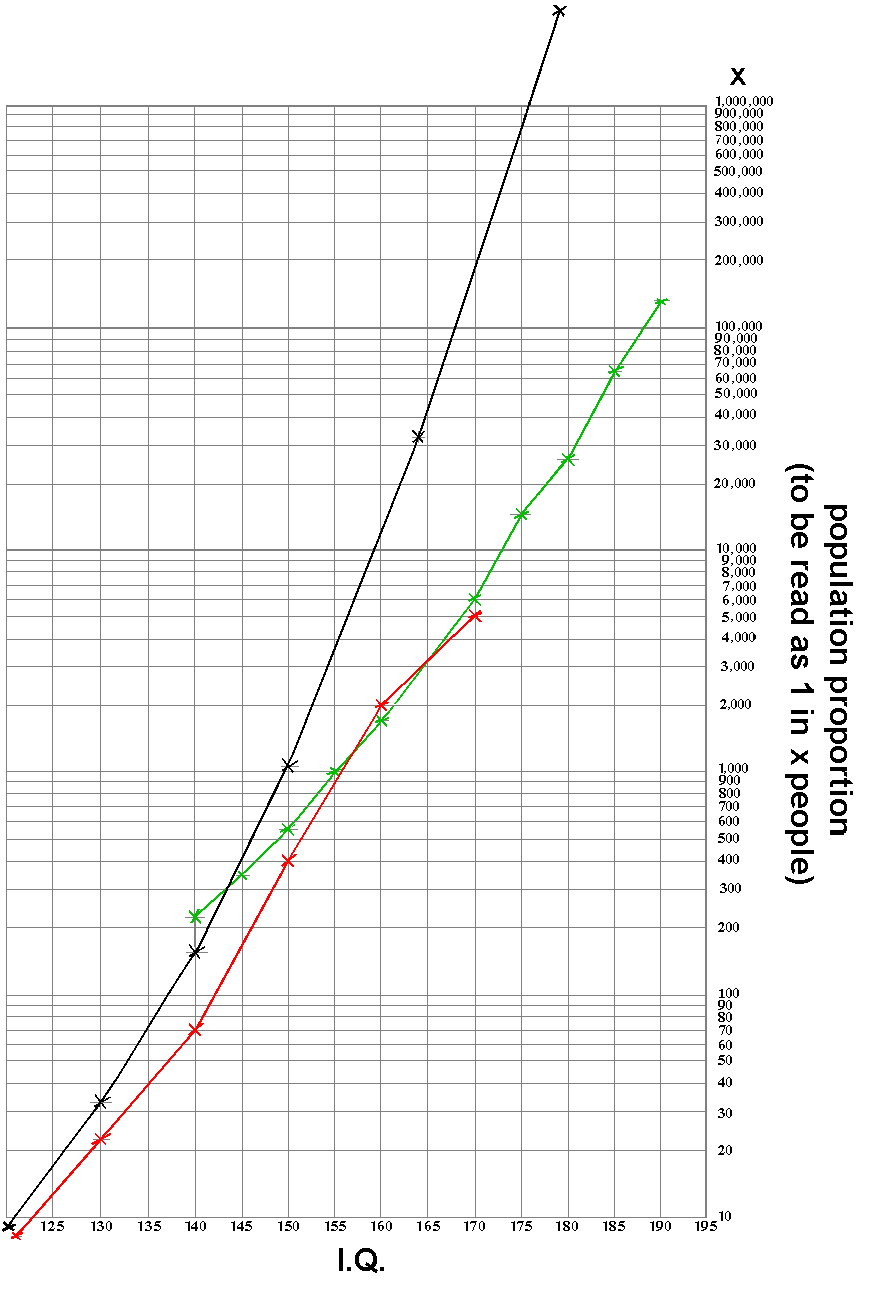
Graph showing the proportion of people in populations[1] measured at particular IQ scores
|
| [1]key to graph: | black line shows the expected distribution of high I.Q., assuming normal distribution and a S.D. of 16 (S.D. = standard deviation) |
red line shows the distribution found by testing during standardisation of Stanford-Binet
Test. |
|
green line is calculated from test reported in Genetic
Studies of Genius, pp.29 —30 and 41 |
|
| Graph based on | [TERMAN, L. & MERRILL, M. (1961) Stanford-Binet Intelligence Scale: Manual for the third revision Form L-M. London: George G. Harrap.] [TERMAN, L.M. (1925) Genetic studies of genius Vol. 1: Mental and physical traits of a thousand gifted children. Stanford, CA: Stanford University Press.] |
Having become suspicious that the distribution of IQ scores at the high end appeared not to conform to normal curve expectations, I graphed the real data, from what I thought to be the most useful and reliable sources, against the normal curve. The results can be seen in the graph above. There are, indeed, a far higher number of people scoring at the high end than would be predicted by the normal curve. I then did a literature check and came across the paper reproduced below. My critique of the use of statistical methods on IQ measurement is presented in ‘intelligence’: misuse and abuse of statistics. I was interested to note that the bulk of the data that I used had been available for most of forty years prior to Cyril Burt’s paper. Nor can I accept that Burt’s suggestion of two ‘types’ of genes can be any more than the wildest speculation at this point. We have, or course, come a very long way since 1963, but it will still be a good while before we have sufficient understanding of genetic/intelligence (or IQ) links and how they interact. Meanwhile, this paper is, in my view, of interest in itself. |
|
| Note 1: | If you examine Burt's alternative suggestions (graph and table of data) for Type IV and Type VII curves, you will find that they come nowhere near to solving the problems and only apply to a limited and irrelevant part of his data. In fact, they vary very little from the standard normal curve and go nowhere near the empiric data shown on my graph above. |
| Note 2: | For those confused by the claims of the widely-advertised IQ club called Mensa, be aware that the Cattell III test used, at least until recently, by Mensa (anomalously) uses a standard deviation figure of 24. Thus, a Mensa ‘IQ’ of 124 is an IQ of 116 on the graph above, and a Mensa IQ of 148 would be an IQ of 132 on the above graph. Instead of 2% of the general population being capable of passing the Mensa test, in truth the figure maybe that 5 to 10% are capable of making this mark. This is because the test results are effected by not being re-standardised for many years, so not taking into account the overall increase in IQ scores in the society at large (the Flynn Effect). Because of the Flynn effect, a Mensa ‘IQ’ result of 148 points for a test taken in the 1950’s, should now (2002) probably be rated nearer to 124 points (s.d. = 24, i.e. an IQ of 116 on the graph above). This because the test used by Mensa was last standardised in the 1950’s. The ‘Mensa IQ’ test is further weakened by being heavily verbal, rather than testing for non-verbal facility. Therefore, it relies largely on education rather than supposed ‘intelligence’ for its results. This anomaly is handled by assigning teenagers extra points, this extra allowance probably also being too great. It is interesting to note that, in terms of IQ scores (data shown in my graph above), a proportion of test-takers would be able to score, in real terms, further above the real level being graded as a Mensa entry pass (IQ score of perhaps 116), as a Mensa entry pass would grade above the score assigned as e.s.n. (educationally sub-normal, once known as mentally defective, which is an IQ score of 68 on the graph).
|
| advertisement |
|
| Vol. XVI Part 2 | The British Journal of Statistical Psychology | November 1963 |
IS INTELLIGENCE DISTRIBUTED NORMALLY?By CYRIL BURT |
||
{p175} Frequency distributions obtained on applying intelligence tests to large samples of the school population are analysed, and compared with those given by the formulae for the commoner types of frequency curve. It is noted that the distributions actually observed are more asymmetrical and have longer tails than that described by the normal curve. The best fit is given by a curve of Type IV: this is in fact the type of distribution we should expect if (as has been argued in earlier papers) individual differences in general ability are determined partly by multi-factorial and partly by uni-factorial inheritance. It follows that the usual assumption of normality leads to a gross underestimate of the number of highly gifted individuals. The conclusions thus drawn are confirmed by a study of data from other sources; and various practical corollaries are deduced. I. PROBLEMIn recent controversies about the abilities both of schoolchildren and of adults a number of questions have repeatedly been raised, some theoretical, others eminently practical, which cannot be answered without some fairly precise knowledge of the way in which individual differences in such abilities are distributed. Hitherto most psychologists and educationists have assumed that the distribution of abilities conforms to the so-called ’normal curve of chance’. In the case of ‘general intelligence’ this alleged normality has often been cited as evidence in favour of some particular hypothesis about the nature or origin of the individual differences observed: on the other hand, several critics have maintained that the apparent normality is merely an artificial consequence of the way mental tests are standardized, and can therefore have no such implications. Nevertheless, it has become increasingly clear that deductions based on the assumptions of normality may at times be highly questionable. In discussing what is called ‘the pool of intelligence’ educationists have varied widely in their estimates of the number of ‘potential geniuses’ available in the child population-potential geniuses being defined for such purposes as ‘those with I.Q.s of 175 or upwards’. Not many months ago, in reply to a question put to him in Parliament, the Minister of Education gave an estimate of ‘little more than one or two in a million’. The assessment, like others of its type, was obtained by employing the normal distribution with a conventional I.Q. scale and a standard deviation of 15 points. But, as the correspondence that followed quickly showed, the figure cited was considered much too low by many headmasters and {p176} educational psychologists, who found it quite out of keeping with the number of pupils with high I.Q.s who passed through their hands.[1] The general acceptance of the theory that individual differences in ability are distributed in strict accordance with the Gaussian curve seems largely due to the advocacy of Thorndike, the acknowledged leader during the earlier decades of the century in the field of educational measurement. In his book, The Measurement of Intelligence, he devotes a chapter and a long appendix to demonstrating the conclusion that, providing the amount of intelligence is measured on a scale of ‘truly equal units’, the distribution should be exactly normal. On applying the chi-squared test to his own measurements he reaches values for P ranging from 0©99 to 0©999,999. Now we used to be warned that “a value of P very near to unity should lead the investigator to suspect his hypothesis quite as much as very small values: such very close correspondences are too good to be true” ([19], p. 423). But in any case the argument in practice tends to become circular: Thorndike’s followers, at least in this country, were very prone to declare that, if the distribution did not conform to the normal curve, that showed that the units were not ‘truly equal’. |
Subsequent work in genetics has since furnished strong theoretical grounds for believing that innate mental abilities are not distributed in exact conformity with the normal curve. So far as they are inborn, individual differences in general intelligence are apparently due to a large number of genes of varying influence. Were inheritance solely ‘multifactorial’, i.e., if the genes consisted solely of numerous ‘polygenes’, each giving rise only to a very small deviation one way or another, then we might reasonably expect the resulting distribution to conform with the ‘normal curve of chance’. But there can be little doubt that some of the genes are responsible for comparatively large deviations; and if their effects were sometimes favourable, sometimes unfavourable, the net result would be to enlarge the tails of the distribution in both an upward and a down-ward direction. However, since the genetic constitution of man is so delicately balanced and adjusted, the effects of these exceptional genes, or of the mutations that produce them, are more likely to be unfavourable than favourable. Hence, the final outcome will be a distribution that is more or less skewed, the longer tail being in the downward direction. Since these exceptional genes are, by hypothesis, comparatively rare, it would seem to follow that, so long as we are concerned with small samples or with the general run of the population, a normal curve might still be trusted to yield a plausible fit. But when we are concerned with the more extreme type of deviation-the exceptionally bright and the exceptionally dull, cases which are {p.177} so infrequent that they are only found in investigations covering very large groups—then the predictions deduced from the normal curve may easily prove mistaken. But—and this is a point which I wish most emphatically to stress—the nature of the distribution is not a matter to be decided (as is so commonly supposed) by mere ‘assumptions’, or even by deductive inference from general principles. It is an issue which can only be settled by an empirical investigation—that is to say, by an ad hoc analysis of data collected from actual surveys. |
Oddly enough, nearly all of those who have joined in these
discussions, whether as critics of the normality hypothesis or as supporters,
seem to have missed the real reason for its popularity. It springs not
so much from theoretical as from practical considerations. The ordinates
and the areas of the curve were long ago calculated and tabulated once
for all by Dr. Sheppard, later H.M. Inspector of Schools [15],
and are now readily accessible in most popular textbooks on mental measurement.
If on the other hand some other type of curve is assumed, the frequencies
would have to be calculated de novo by each investigator for
every fresh research. In the following analysis the chief novelty is the
detailed comparison of the frequencies actually observed with theoretical
values specially computed from the formulae for a curve of Type IV. Indeed,
the primary object of the paper is not so much to supply better estimates
for the number of children possessing this or that grade of intelligence,
but rather to illustrate the practicability of more adequate methods of
statistical analysis. II. DATA AND METHODSThe earliest of the statistical analyses which were carried out to gain light on the foregoing problems seemed plainly to indicate that the distributions of ability among school children by no means conformed to a strictly normal distribution ([1], p. 34; esp. footnote 2, [2], pp. 160f.). The two anomalous characteristics which might be expected to result from a combination of ‘multifactorial’ with ‘unifactorial’ inheritance—the elongated tails and the downward asymmetry—were already discernible in the frequency curves then obtained. The chi-squared test was regularly applied; and, wherever the samples were sufficiently large, the divergences from strict normality proved to be statistically significant. However, these initial surveys were merely experimental. The types of test used for such purposes—the original Binet-Simon scale and the earliest group tests—were predominantly verbal, and, as was to be anticipated, could claim no very high reliability or validity. On the whole and in this country the most efficient procedures now available for the purpose would appear to be the later British adaptations of the Stanford-Binet scales. Accordingly in what follows I shall confine myself mainly to data procured by this means. In a previous publication [4] I have already reported results obtained during investigations undertaken
to secure material for an English standardization of the original Stanford-Binet
scale. It was then shown, not only that the discrepancies {p178} were statistically significant, but also that the values for the usual
criteria (the so-called beta coefficients) indicated that the distribution
should be regarded as belonging to Pearson’s Type IV. Further results
have since become available during investigations with the new revised
Stanford-Binet tests [16].
The total number of children assessed in the course of all these surveys
amounts to 4,665. Their distribution is shown in the first column of Table
I. It is plainly skewed, with a prolonged lower tail. Of the entire group
more than 10 per cent have I.Q.s under 80; only 7©7
per cent have I.Q.s over 120. TABLE I. OBSERVED AND THEORETICAL
DISTRIBUTIONS |
I.Q. |
Observed |
Theoretical |
|||
Before screening |
After screening |
Normal |
Type VII |
||
Below 30 |
0©11 |
0©02 |
— |
0©03 |
0©01 |
30— |
0w06 |
0©02 |
— |
0©03 |
0©01 |
35— |
0w09 |
0©04 |
— |
0©05 |
0©03 |
40— |
0w21 |
0©11 |
0©01 |
0©09 |
0©05 |
45— |
0©23 |
0©16 |
0©03 |
0©14 |
0©09 |
50— |
0a39 |
0©27 |
0©10 |
0©27 |
0©17 |
55— |
0co62 |
0©46 |
0©26 |
0©43 |
0©33 |
60— |
0e 77 |
0©64 |
0©62 |
0©74 |
0©62 |
65— |
1©35 |
1©24 |
1©32 |
1©30 |
1©71 |
70— |
2a34 |
2©08 |
2©54 |
2©28 |
2©16 |
75— |
3r97 |
3©40 |
4©37 |
3©71 |
3©77 |
80— |
6d 41 |
5©70 |
6©75 |
5©86 |
6©16 |
85— |
9©01 |
9©07 |
9©37 |
8©78 |
9©18 |
90— |
11o60 |
11©96 |
11©61 |
11©47 |
12©13 |
95— |
13r01 |
13©42 |
12©94 |
13©79 |
14w02 |
100— |
13g 42 |
13©84 |
13©01 |
14©11 |
14w09 |
105— |
12©67 |
13©07 |
11©66 |
12©57 |
12w18 |
110— |
10©01 |
10©33 |
9©41 |
9©66 |
9©22 |
115— |
6©00 |
6©19 |
6©76 |
6©38 |
6a18 |
120— |
3©45 |
3©56 |
4©38 |
3©92 |
3b79 |
125— |
1©97 |
2©03 |
2©54 |
2©15 |
2e16 |
130— |
1©20 |
1©24 |
1©32 |
1©12 |
1l17 |
135— |
0©60 |
0©62 |
0©62 |
0©57 |
0a62 |
140— |
0©28 |
0©29 |
0©26 |
0©28 |
0r33 |
145— |
0©11 |
0©11 |
0©10 |
0©13 |
0d17 |
150— |
0©06 |
0©07 |
0©03 |
0©06 |
0©09 |
155— |
0©04 |
0©04 |
0©01 |
0©04 |
0o05 |
Above 160 |
0©02 |
0©02 |
— |
0©04 |
0r05 |
Total |
100©00 |
100©00 |
100©00 |
100©00 |
100g00 |
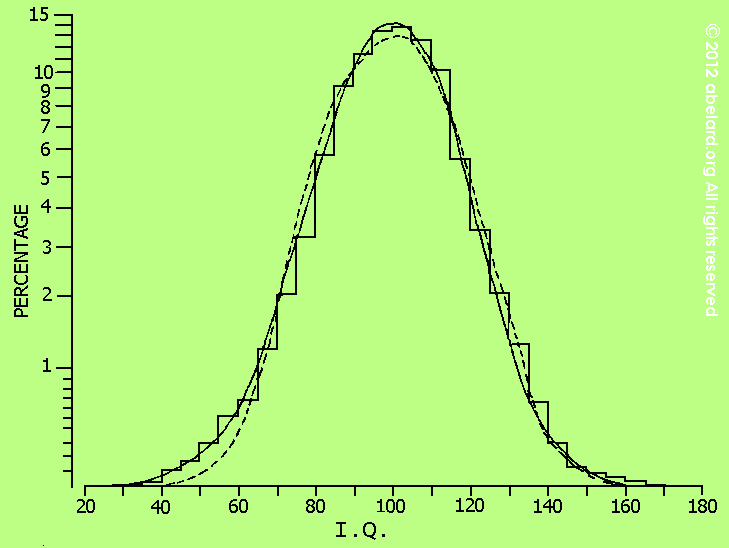
However, with each of the component batches we have endeavoured to eliminate all those cases in which there was the smallest reason to believe that the low I.Q. was mainly or largely due to non-genetic causes, either environmental, {p179} pathological, or accidental (e.g. caused by injury at birth).[2] The number remaining [3] after these eliminations were made was 4,523. The data for this composite group have now been analysed by Miss Baker along the lines which I adopted in reporting the separate surveys. To conform to the conventional scale now in current use all the I.Q.s have been restandardized so as to yield a standard deviation of 15 points.[4] {p.180} The distribution of the group, after this preliminary screening had been carried out, is shown in the second column of Table I. In I.Q. points the mean is almost exactly 100, and the standard deviation almost exactly 15 (calculated to two decimal places they are 100 ©07 and 15©09 respectively). These values of course are the results of the standardization. The amount of individual variation, however, differs in the two different directions: in the upper half of the curve it corresponds to a standard deviation of only 14©8, and in the lower half to one of 15©4. Column 3 in the table shows the theoretical distribution calculated from the usual tables for the normal curve and based on the calculated mean and standard deviation given above. It is at once obvious that the frequencies found in the survey rise in the centre to too sharp a peak and exhibit tails that are far too widely and unequally spread out for the observed distribution to be regarded as typically normal. On applying the usual test for goodness of fit, we find 79 = l07 ©3, and consequently, if the distribution in the general population were strictly normal, it would be well over a million to one against discrepancies so large as those observed occurring as a result of the mere chances of random samples. At the same time it will be noted that, with a much smaller sample (e.g., one which only justified us in calculating the percentages to one decimal place and contained no individuals with an I.Q. over 150 or under 60—as indeed is the case with many of the frequency tables published for surveys), the normal curve would provide a very plausible fit. (See Figure 1, which shows |
Figure 1 [above]: Observed and theoretical distribution (Type IV continuous line; Normal Curve dotted line) {p.181} the observed frequencies after the doubtful cases have been eliminated by screening, and the best-fitting curves of the ‘normal’ type and of type IV.) In order to discover to what class of curve the distribution belongs, we have here followed the same procedure as before. Using the notation suggested by Karl Pearson we find ?( (the criterion for skewness) = 0©048, and ?) (the criterion for kurtosis) = 3©9l8. This suggests that the curve is either Type VII or Type IV. Taking Fisher’s forms of the criteria, we obtain g1 = — 0©219 + 0©036 and g2 = 0©9l8 + 0©073, and from these values or from the betas we obtain [5] % = 0©007. Curves for which the criterion % lies between 0 and 1 are classified by Pearson as belonging to Type IV. This is the only type in his series which is ( i ) of unlimited range in both directions and at the same time ( ii ) asymmetrical and ( iii ) leptokurtic, i.e., peaked. To determine how closely a hypothetical curve of this type will fit the actual data it will be necessary to compute the theoretical frequencies. The method adopted is virtually that which I described and used in my previous reports, and is based (with minor modifications) on the second of the two working procedures discussed by Palin Elderton ([6], pp. 67f). Instead of the simpler formula which he uses we have preferred the slightly more complicated expression in which the deviates to which the frequencies refer are deviates from the mean instead of from the arbitrary origin, namely, y = y& }1+ ]<— =[9{* p exp{ —Â ÖÝÐ-:(¦ /ª — Â/¾) } (1) where §& is the ordinate at the mean, and r, m, v, and a are constants computed from ?( and ?), and ª varies with the standard deviation. With the present data the values are ¾ =10 a184, ¹ = 6©092, Â = 1©527, and ª = 9©501. This yields values for the ordinates at mid-points of the successive intervals into which the total range is subdivided. To effect a valid comparison we need areas rather than ordinates; and for this purpose we have applied the formula |\ § z¦f>§z ;( + 22 §z + §z"() (2) where yz denotes the
ordinate at the mid-point of the interval and §z;( and §z"( the ordinates next below and next above. Elderton observes that the calculation
of the values relating to this curve “needs considerable care: it
is”, he adds, “the most difficult of all the Pearson-type
curves”. We have found the labour lengthy rather than difficult;
but admittedly there are ample opportunities for slips and mistakes. |
{182}
III. RESULTSLet us now glance at the results and conclusions reached on adopting these somewhat novel formulae. The detailed frequencies computed by the foregoing equations are shown in the fourth column of Table I. 79 is now only 18©2; P = 0n57. The fit is perhaps not quite so close as that obtained by Karl Pearson for distributions derived from physical measurements. But it is clear that the discrepancies between the theoretical values and the values observed may now quite well be due to the chances of sampling, and that the agreement is far better than that commonly obtained in cases of mental measurement. To estimate the proportional number of individuals having I.Q.s above any borderline which lies outside the range of Table I—e.g., the borderline of 175 I.Q. mentioned in the question put to the Minister of Education—we must undertake some kind of extrapolation. With the aid of the formula we can extend the theoretical calculations beyond the limits reached by our sample and sum the areas. Table II shows the chief results. Here the figures in column ii represent the cumulative frequencies thus obtained, i.e., the proportional numbers reaching or exceeding the I.Q. specified in the left hand margin. Column i gives the proportions deduced from Pearson’s tables for the normal curve, assuming as before a standard deviation of approximately 15 I.Q. It will be seen that according to our estimates the number having I.Q.s of over 160 is more than ten times the number deduced from the normal curve, and that, instead of the proportion of those with I.Q.s of 175 or over being only 3 or 4 per million, it rises to nearly 77 per million. At the present day the male school population in England and Wales amounts to rather over 4 millions. That would yield more than 300 boys of school age with I.Q.s over 175. Among the female population, just as the number of defectives is smaller than that obtaining among the males, so apparently is the number of geniuses. But in any case, the total number of children reaching the high level specified cannot be far short of five or six hundred. TABLE II. THE ESTIMATED PROPORTIONS OF THE POPULATION REACHING OR EXCEEDING THE BORDERLINE SPECIFIED |
Borderline |
Number per million |
|
160 |
31©7 |
342©3 |
175 |
3©3 |
76©8 |
190 |
0©1 |
19©4 |
200 |
<0©001 |
6©2 |
It is however of interest to consider whether a simpler formula might not furnish a reasonable fit. We have seen that, when pathological cases are eliminated, the degree of asymmetry becomes comparatively slight; both ?(and % have decidedly low values. Accordingly let us ask what type of curve would give the closest fit if we assumed that the apparent asymmetry resulted {p183} solely from errors of sampling. This would imply that the true value of ?( and % is zero. In that case the constant v, which is based on ?(, would likewise be zero. The exponential factor in eqn.(1) then becomes unity, and the equation reduces to the extremely simple form —the formula for a curve of Type VII. The equations for the two constants are correspondingly simplified. Substituting the numerical values for ? and @ (the standard deviation) we now obtain and With the aid of a table of logarithms the theoretical frequencies can be readily computed. The figures obtained are shown in column 5 of Table I. Applying the usual test we have 79 = 23, and P = 0©28. The fit is decidedly better than that given by the normal curve. If therefore the distribution in the general population was in fact a distribution of Type VII, the probability that discrepancies as large as this or larger would occur as a result of random sampling would be just under 1 in 3. The well-known relation between the very simple formula thus reached (eqn. 3) and the more familiar formula for the normal curve is worth a passing comment for the benefit of training college lecturers and others concerned with elementary courses on statistical psychology. The relation turns on the fact that, as n increases indefinitely, the limit of (1 + 1/º )q is the number °, the base of the natural logarithms, and the limit of (1 — ¨/ ·)q is °-v. Now let us write eqn. (4) in the form a9 = — @9¶9,then eqn. (5) gives m = — 5k¶9 (5 — 9/?)); so that, as ?) approaches 3, ¹ approaches — 4k¶9, and ¶9 increases indefinitely. In that case eqn. (3) will take the form y/y& = ]1—0 [6$8 or, putting z = ¦9/2@9 and n = 4k¶9 y/y& = e -u8/t8 when ¶9 becomes indefinitely large. Moreover, it will be noted that, if in eqn. (3) we
put ª9 = n and m = 4(n +1), we obtain the equation
which expresses the distribution of Student’s t. Suppose
we take m as approximately 6; then n will be 11; and,
on referring to the table for t given in Yule and Kendall ( [19],
p. 537), it will be seen that with a standard deviation of t = 11, the values in the column for n = 11 yield on subtraction
proportionate frequencies which are not unlike those in column 4 of Table
I, and so offer a rough fit to data such as the present. |
{p.184}
IV. SUPPLEMENTARY EVIDENCECritics who still wish to defend the hypothesis of strict normality may perhaps be inclined to suggest that, since our list of observed frequencies has been obtained from a composite sample, the two peculiarities We have noted—the asymmetry and the elongated tails—might well be just the incidental consequences of the ways in which the constituent groups have been selected and combined. In reply may I point out that each of the constituent groups themselves showed the same features, and in particular, with the largest group of all—based on a survey in which we sought to include the entire child population between the ages of 6©0 and 11©0 residing in a representative electoral division of London—the calculated values for the beta coefficients indicated, even more clearly, a curve of Type IV (cf. [4], p.170)? It is instructive to compare the results obtained in these and later surveys with those found by the American investigators while standardizing the latest revision of the Stanford-Binet tests, i.e., the so-called Terman—Merrill scale ([10], pp.21—23). For this purpose a group of just under three thousand children was tested with the two alternative forms of the scale—L and M. With form L, the I.Q. ranged from 35 to 170, with form M from 35 to 165. The average of the whole group, however, was appreciably higher than ours—104©0 I.Q. with form L and 104©4 with form M. This means that the range runs from 70 points below the average to 60 or 65 points above—limits which are not very different from our own. On applying the chi-squared test for agreement with normality, McNemar found, for form L, P = 0©03 and for form M, P = 0©005. Thus, particularly in the latter case, the divergences from the normal curve are fully significant. The discrepancies of the fit, though numerically large, are by no means obvious to the eye when inspecting the various graphs that show for each scale the observed frequencies superimposed on the best-fitting normal curve: (op. cit., [10] figs. 1 and 2, p.19). The relevant constants are as follows. For form L, ²( = 0©028 + 0©045, and for form M, 0©029 +0©045; for form L, ²9 is 0©346 + 0©090 and for form M, 0©298 + 0©090. Thus both frequency distributions are significantly leptokurtic as the diagrams certainly suggest on a closer examination: both seem too sharply peaked to be regarded as normal, and the frequencies at the end of either tail extend too far. On the other hand, the criterion of skewness is in both cases non-significant. However, as McNemar points out, there were several unavoidable defects in the sampling. The distribution, we are told ([17], pp. 15f.), contained an unduly small proportion of children from the lowest occupational groups: indeed, to judge by the table (loc. cit., [17 p.14) the percentage in the lower group (unskilled day-labourers) was apparently only one-third of what it should have been. Moreover, since the sample was restricted to schools-and indeed to what are described as ‘average schools’—and therefore did not include subnormal children living at home or in institutions, the number of defective as well as of dull and backward pupils must have been disproportionately small. Had they been included, the downward asymmetry, which appears in 4 out of the 6 constituent groups, would be much more clearly marked. McNemar himself makes no attempt to identify the {p185} type of distribution shown. He expressly refrains from drawing any conclusions from these data concerning the probable distribution of intelligence, and merely observes that “the I.Q.s are approximately normal in distribution”. And of course, so long as we are dealing with the ordinary run of children in the primary and secondary schools, the assumption is not likely to lead us far astray.[6] However, scattered throughout the relevant literature there is a good deal of additional evidence which strongly suggests that for those who are definitely subnormal the relative frequencies deduced from the normal curve are far too low. In his discussion of the ““medical grouping of institutional cases” Penrose, for instance ([11], p. 45), points out that “far too many individuals exist, whose abilities are more than 3 or 4 times the standard deviation below the normal mean, to be fitted under a Gaussian curve: on that assumption only about 1 idiot among 10,000 and 1 imbecile among 6 could belong to a normal population with a standard deviation of 15 I.Q. points”: with his classification, as his table shows, the ‘observed percentages’ are 0©04 and 0©4 respectively, whereas a normal distribution would predict only 0©000,004 and 0©06. Unfortunately in official reports on mental deficiency the figures commonly given have been collected for administrative purposes, and relate only to those defectives who have been formally ‘ascertained’. Nearly always they are expressed as fractions of the total population not of the relevant age groups; nor do they, as a rule, attempt to distinguish between the cases that are undoubtedly pathological and those that are presumed to be wholly or partly of genetic origin. Moreover, owing to the variation in the standard deviation and the inadequacy of the tests employed, the I.Q.s used in defining the border-lines are by no means equivalent to the I.Q.s on the conventional scale that is now in use among psychologists.[7] When a reasonable allowance is made for these disturbing factors, the estimates for the incidence of subnormality, as shown in nearly all the published surveys, both British and American, nearly always suggest proportional numbers far {p186} higher than those which would be deduced from a distribution that was strictly normal (see [5] and refs.) This point, however, has been sufficiently stressed in earlier publications. The exact determination of assessments for supernormal ability has received far less consideration from previous investigators. In recent discussions about the ‘national pool of ability’ and the ‘need for more adequate methods of selecting and training the undiscovered reserves of ability’ attention has been chiefly concentrated, both in this journal and in the popular press, on the numbers at the higher end of the scale-more especially the number of potential entrants to the grammar schools and to the universities, i.e., of those whose abilities rise above levels of about 110 and 130 I.Q. Here I should like to insert a special plea for a more adequate recognition of the needs and the numbers of those I have called the ‘exceptionally gifted’. They form a group who constitute one of the nation's most valuable assets, and whose special educational requirements have hitherto been grossly neglected. The average I.Q. of pupils with I.Q.s over 160 (about 170 I.Q.) must be as far above the average I.Q. of the general mass of grammar school children (about 122 I.Q.) as the average of these selected children is above that of the educationally subnormal (i.e., pupils with I.Q.s below 85, whose average would be about 77 I.Q.). Such highly gifted individuals must therefore feel as much out of place in the ordinary grammar school as the grammar pupils would in a class of dull and backward youngsters; and this is fully borne out by evidence gathered from such youngsters while still at school, or later on when, as adults, they have reported or recorded their school experiences. Let us therefore glance first of all at one of the very few factual inquiries relating to these exceptionally gifted children. In Terman’s investigation the initial aim was to select and study those whose I.Q.s would place them “well within the top 1 per cent of the school population”. The working borderline was fixed at 140 I.Q. Of those selected the number with I.Q.s of 170 or over amounted to 6©7 per cent, i.e., between 300 and 600 per million in the general population according as we interpret "well within 1 per cent". The proportion, as several reviewers pointed out at the time, was unexpectedly high; and perhaps some allowance should be made for the fact that the average level of the population in the cities of California was said to be 4 or 5 points above the general average of the U.S. population, while the standard deviation (with Terman’s age-allocations) was nearer 16 points than 15 ([17], pp.19, 44f). In a later search for exceptionally gifted pupils in New York City—a search described as by no means ‘exhaustive’—Dr. Leta Hollingworth found at least a dozen with I.Q.s over 180, i.e. a proportion of about 20 per million. Deviations of this size, she tells us, would be expected “only once in more than a million times if the distribution corresponds to Quetelet’s curve of probability”; but, she adds, “it seems more likely from existing data, that children who test above 180 I.Q. are present in greater frequency” ([8], pp. xiii, 23f.). Still more recently the Counseling Centre of New York University reported a follow-up study of a batch of children {p187} who at the time of testing (approximately age 5) had I.Q.s of 170 or more; and that inquiry over a hundred cases were discovered. In this country the figures I and my co-workers have obtained in the course various surveys have varied widely from one area to another. In my earliest inquiries, carried out with the assistance of the Department for the Training of Teachers at Oxford, I found, in a single age-group (aged 9½ to 10½) numbering , approximately 1,600 children in all, six children with test-scores equivalent to an I.Q. of 175 or above, nearly 0©4 per cent; nearly all of them came from one particular preparatory school which catered specially for the children of dons. On the other hand, in Liverpool, within a group of the same age but nearly eight times as large and consisting solely of pupils attending public elementary schools, not a single child of this high level was discovered; outside the elementary schools, however, a number of such cases were located, and we estimated that their proportional frequency amounted to just under 30 per million. In my first survey of Council schools in London I found 3©24 and 0©45 per cent with deviations exceeding twice and three times the standard deviation respectively, i.e., with I.Q.s of 130 and 145, instead of 2©27 and 0©13 per cent as we should expect with a strictly normal distribution ([2], pp. 161, 174f.; 4th ed., pp. 199, 218f.); the London child whom we discovered with an I.Q. of 190 (the case cited by Dr. Hollingworth in the discussion just mentioned) was encountered in a private school. However, at the time of the earliest L.C.C. surveys comparatively few parents belonging to the professional classes sent their children to the public elementary schools, and the test then used—which consisted either of those forming the original Binet-Simon scale or those adopted in our first attempts at group testing—scarcely did justice to children who were exceptionally bright. At a later date, when carrying out inquiries for the Consultative Committee of the Board of Education, we found at what were then called ‘secondary schools’ 23 boys between the ages of 11 and 16 with I.Q.s of 175 or over—most of them attending ‘Headmasters’ Conference Schools’. But the parents of two of these ‘exceptionally gifted’ children lived outside London, and three others had come London specifically for the sake of the child's education, which reduces the number of genuine Londoners to 18. In the County of London the male population between those ages then amounted to just over 200,000 which would suggest a proportion of about 90 per million.[8] Finally, for the benefit of readers who may feel doubtful about a purely statistical approach we may try an alternative method of estimation by following the lines adopted by Galton in his early study of genius ([7], p.34). With this aim in view let us consider a single generation —that of men born in the {p188} British Isles during the first 30 years of the 19th century. I choose this period rather than any other, first because with any later period it would be hard to compile an agreed list of the most eminent persons, and secondly because during an earlier period it is highly likely that many geniuses of humble origin, such as Faraday and Dickens, might have failed to develop or manifest their true powers; nor would it be easy to secure satisfactory evidence for assessing their I.Q.s. Since few eminent people succeed in demonstrating their claim to the title of genius before they reach middle life (say 45), we must confine ourselves to those males who survived to at least that age; and for simplicity of calculation let us keep to round figures. The total number in the generation selected would be about two and a half millions. Now in the case of five men of eminence born within the period chosen—John Stuart Mill, Sir William Rowan Hamilton, Lord Macaulay, Lord Kelvin, and Sir Francis Galton—we have detailed records of their early childhood sufficient to indicate that their I.Q.s must have been approximately 200. This is already a proportion of about 2 per million. But many other equally famous names will spring to mind-men born within the same dates who reached the same level of eminence, but for whom the records of childhood are less informative. Looking through the Dictionary of National Biography, we find that, roughly speaking, there were well over a dozen in each of the following categories:
This makes about 75 in all out of 2,500,000, or almost 30 per million. We are, however, frequently assured, that, owing to the handicaps of poverty and social class, there must have been in the ‘under-privileged’ groups quite as many ‘mute inglorious Miltons’ who had no opportunity to develop their latent abilities, and so died with all their music in them. To make allowance for these unknown abortive geniuses we ought at least to double the figures. We should then reach a proportion of about 60 per million. However, a critic may object that we have hit on an unusually productive
era.[9] I myself should be inclined to agree that,
owing to the diminished birth-rate among the professional and upper classes
and the mortality during the first world war, the proportion of those
with I.Q.s of 200 or more would today very probably be smaller. Accordingly
let us meet this criticism by lowering the borderline rather than the
per-million age. We might still reasonably maintain that the proportion
with I.Q.s over 175 would reach, and in all likelihood exceed, the figures
just cited. Thus the estimate reached by these broader considerations {p189} would seem to be quite in
keeping with that which we deduced from our Type IV curve—viz. somewhere
between 60 and 80 per million. |
| advertisement |
V. SUMMARY AND CONCLUSION
|





REFERENCES |
|
| [1] | BURT, C. (1917). The Distribution and Relations of Educational Abilities. London: P.S. King. |
| [2] | BURT, C. (1921). Mental and Scholastic Tests. London: P.S. King. 4th ed. (1962), Staples Press. |
| [3] | BURT, C. (1935). The Subnormal Mind. London: Oxford Univ. Press. |
| [4] | BURT, C. (1957). The distribution of intelligence. Brit. J. Psychol, XLVIII, 161-175. |
| [5] | CLAREE, A. M. and A. D. B. (1958). Mental Deficiency. London: Methuen. |
| [6] | ELDERTON, W. P. (1938). Frequency Curves and Correlation. Cambridge: At the University Press. |
| [7] | GALTON, F. (1869). Hereditary Genius. London: Macmillan. |
| [8] | HOLLINGWORTH, L. S. (1942). Children Above 180 IQ. New York: World Book Company 1975 Ayer Co. Pub, 0405064675 $35.95 |
| [9] | MAYER-GROSS, W., SLATER, E., and ROTH, M. (1954). Clinical Psychiatry. London: Cassell. |
| [10] | McNEMAR, Q. (1942). The Revision of the Stanford-Binet Scale. New York: Houghton Mifflin. |
| [11] | PENROSE, L. S. (1954). The Biology of Mental Defect. London: Sidgwick & Jackson. |
| [12] | Report of the Mental Deficiency Committee (1929). London: H.M. Stationary Office. |
| [13] | Scottish Council for Research in Education (1933). The Intelligence of Scottish Children. London: University of London Press. |
| [14] | Scottish Council for Research in Education (1949). The Trend of Scottish Intelligence. London: University of London Press. |
| [15] | SHEPPARD, W. F. (1903). New Tables of the probability integral. Biometrika, II, 174—190. |
| [16] | TERMAN, L. M. (1925). Mental and Physical Traits of a Thousand Gifted Children. Stanford: Stanford. Univ. Press. |
| [17] | TERMAN, L. M. and MERRILL, M. A. (1937). Measuring Intelligence. London: Harrap. |
| [18] | THORNDIKE, E. L. et al.(1927). Measurement of Intelligence. New York: Teachers’ College, Columbia University. |
| [19] | YULE, G. U. and KENDALL, M. G. (1937). An Introduction to the Theory of Statistics. London: Griffin. |
The British Journal of Mathematical and Statistical Psychology and The British Psychological Society. |
END NOTES
|
© abelard, 2002, 31 july the address for this document is ' 8545 words |
| latest | abstracts | briefings | information | headlines | resources | interesting | about abelard | ||